Recent Posts

Power saving and screen locking in Sway
Pre-requirements
To enable power saving rules described in this post, you need to install these tools:
- swayidle - IDLE management daemon
- swaylock or swaylock-effects - screen locking utility for Wayland compositors
- ddcutil - program for managing monitor settings, such as brightness, color levels, and input source through DDC/CI (Display Data Channel Command Interface)
- power-profiles-daemon
- Makes power profiles handling available over D-Bus
- cpupower - shows and sets processor power related values
Rules
The goal is to implement power saving rules for IDLE state:

Współpraca
Oferuję kompleksowe usługi projektowania, realizacji i utrzymania aplikacji web w zakresie:
- server side Python/Django
- client side ReactJS + BlueprintJS (lub inny framework UI)
- projektowania i budowania relacyjnych baz danych (PostgreSQL)
- realizacji i utrzymania środowiska wdrożeniowego (konteneryzacja, monitoring, obsługa awarii)
- możliwość współpracy długoterminowej
Wspierany stos technologiczny:
- Python, Django, FastAPI
- Javascript/JSX, ReactJS
- FastAPI, Django REST Framework
- PostgreSQL, Apache Cassandra
- Redis, Memcached, RabbitMQ
- Celery, Django RQ
- Grafana, Prometheus, Alert Manager, Sentry
- Docker, Kubernetes
Zapraszam do kontaktu:

Migrating from i3wm to Sway
i3 will never support Wayland due to a difference between Xorg and Wayland architecture. Sway is a i3 compatible Wayland server implementation.
Long story short - Wayland is a just protocol, which must be implementend in a compositor/window manager, where Xorg is a X11 display server which can run different window managers top of it.
There is no single common Wayland server like Xorg
Motivation
X11 is being quite old and unsafe protocol, and Xorg is the implementation based on multiple extensions and hacks. Almost nobody wants to support it, and all major desktop environments are slowly switching to Wayland .

Tajemnice Atari 5200
Ciekawa opowieść dr Grabarczyka na temat historii Atari, niekoniecznie dobrych pomysłow i odrobiny “marketing bullshitu” tamtych czasów. Polecam! 😊

Godot introduces Lightmap GI shadowmasking
Today (12 Dec 2024) a lightmap shadowmasking feature , created by BlueCube3310 , was merged to the Godot’s upstream. It means that Godot 4.4 release will bring this feature for everyone. Check Godot blog for upcoming annoucements!
Lightmap shadowmasking
Lightmap Shadowmasking is a technique used in real-time rendering engines (like Unity , Unreal Engine , and now Godot ) to combine baked lighting with real-time shadows for efficient lighting calculations. It helps balance performance and visual fidelity by minimizing the number of real-time light calculations required during gameplay.

Queuing background tasks in Django
RQ and Django-RQ
RQ is a lightweight Python library for managing background tasks. It allows developers to offload time-consuming operations - such as sending emails, processing images, or performing heavy calculations - to background workers. These workers process the tasks asynchronously, improving the performance of your application by keeping the request-response cycle fast and responsive.
DjangoRQ is an integration package that simplifies using RQ with Django . It provides tools for managing task queues, workers, and even a built-in admin interface to monitor tasks.

Tailwind is badly designed
I heard about Tailwind and looking at its documentation I thought there was something wrong with it. At the time I was surprised by the many fragmented classes that had to be set. Now that I look at it more closely, HTML semantics are basically not used, contextual styling is almost non-existent, and instead there are hundreds of CSS classes that have to be repeated with almost every tag. This results in a terribly large HTML source (“HTML bloating”), slows down development (you have to remember and constantly rewrite hundreds of classes), makes documents unreadable. And by having to repeat classes for elements of a certain type Tailwind violates DRY .

Nowy silnik bloga po disasterze
Mój blog zdążył zniknąć z sieci, po tym jak OVH wskutek ich błędu usunęło mój serwer fizyczny. Powodem usunięcia serwera był brak powiadomienia o wyłączeniu usługi, które zawsze przychodzi, i od którego jest 7 dni na uregulowanie płatności i przywrócenie maszyny. Reklamacja została oczywiście odrzucona, a kopii danych nie było.
Ludzie dzielą się na tych, którzy robią backupy i na tych, którzy dopiero zaczną je robić
Robienie backupów nie jest procesem trywialnym. Jest kosztowny, wymaga infrastruktury, zaplanowania, i opracowania procedur odzyskiwania danych.
Headless CMS explained
Jakie są podstawowe różnica między klasycznym CMS a headless CMS?

PHP - Fractal of bad design (2024)
W świecie PHP brak istotnych zmian. Hipotetyczne dokumenty księgowe wystawiane 30 lutego wpisują się (niestety) w smutny kanon.
Jest to ciekawy i dość poważny błąd standardowej biblioteki funkcji języka, ponieważ może pozostać niezauważony. Nieistniejąca (nieprawidłowa) data jest bowiem wewnętrznie korygowana bez przerwania przetwarzania błędem lub wyjątkiem. Język zgłasza błąd dopiero wtedy, gdy spróbujemy ustawić dzień powyżej 31.
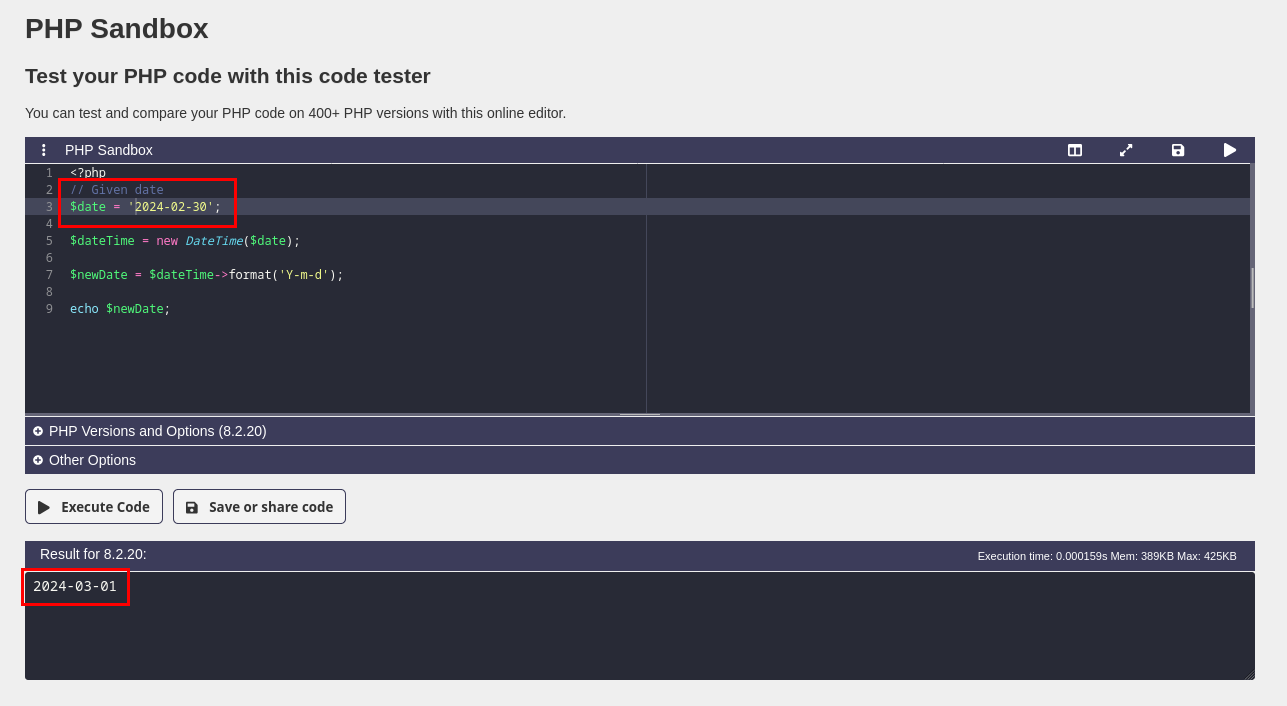
Równie problematyczny jest brak wyjątków, czyli do tej pory w PHP został zachowany status quo, tj. niespójny error handling (parse error, recoverable error, fatal error, exceptions):