PHP - Fractal of bad design (2024)
W świecie PHP brak istotnych zmian. Hipotetyczne dokumenty księgowe wystawiane 30 lutego wpisują się (niestety) w smutny kanon.
Jest to ciekawy i dość poważny błąd standardowej biblioteki funkcji języka, ponieważ może pozostać niezauważony. Nieistniejąca (nieprawidłowa) data jest bowiem wewnętrznie korygowana bez przerwania przetwarzania błędem lub wyjątkiem. Język zgłasza błąd dopiero wtedy, gdy spróbujemy ustawić dzień powyżej 31.
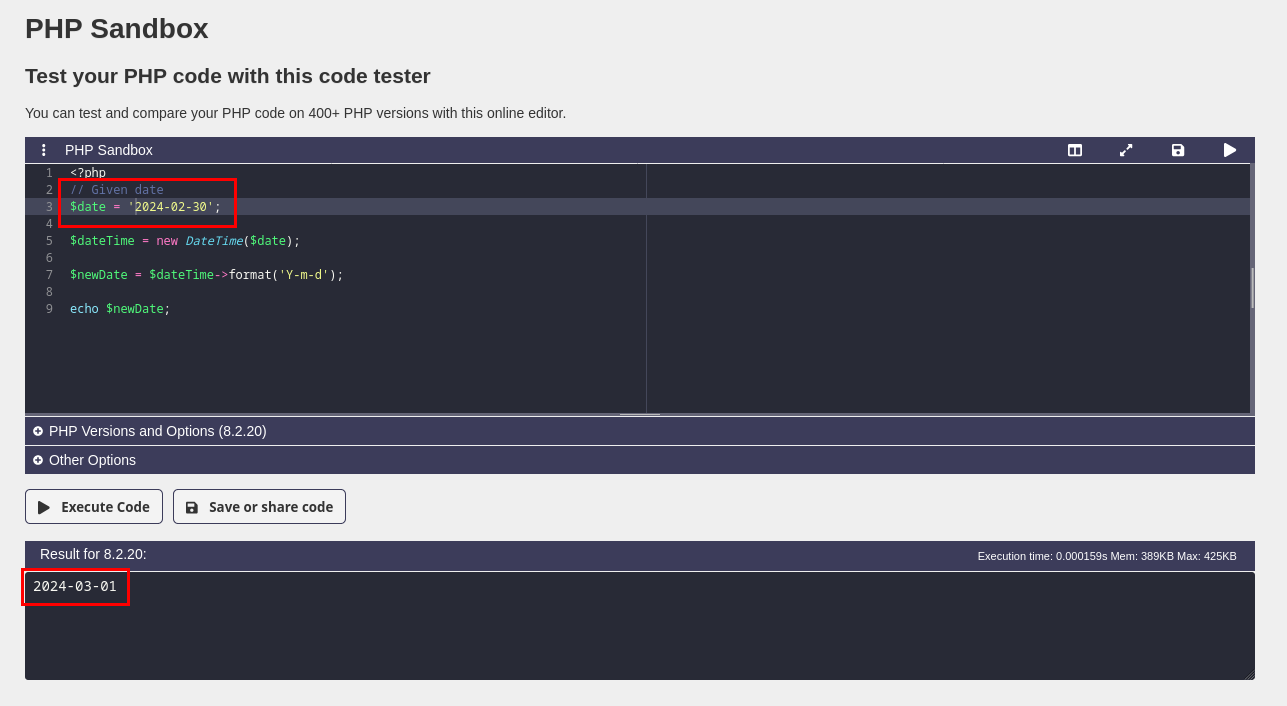
Równie problematyczny jest brak wyjątków, czyli do tej pory w PHP został zachowany status quo, tj. niespójny error handling (parse error, recoverable error, fatal error, exceptions):
Build the API with FastAPI top of Django
Even though these two tools seem to be mutually exclusive, they are not. There is possibility to omit Django’s http server and relay all HTTP traffic to FastAPI’s ASGI application. These are the goals of the new package Django FastAPI Bridge
Wait, isn’t Django too old for FastAPI?
If you type “Django and fastapi” into Google you will get results that are simply misinformation. Speaking gently - they’re outdated or written by persons without an experience (a real plague these days):
Reducing a mess generated by vim-ale
In case of mess in your editor window, just add this line to your .vimrc:
let g:ale_virtualtext_cursor = 'disabled'
a mess in vim A mess in VIM (look at these red inline error messages)
The root cause of the issue
Some creative guys thought that mixing warning messages with code makes some sense and increases readability, and someone smart enough implemented it (to the misfortune of mankind).
ReactJS rapid development
ReactJS to moje odkrycie 2019/2020. Po gruntownej analizie plusów dodatnich i ujemnych Angular i ReactJS wybrałem ten ostatni. AngularJS 1.x znałem dosyć długo i doskonale zdawałem sobie sprawę z jego minusów, a te są najważniejsze. Przecież to od nich zależy szybkość developmentu i długofalowe utrzymanie projektu. AngularJS poległ pozostawiając nieczytelny i opuchnięty kod, a two-way bindingiem i watcherami doprowadzał do wysokich temperatur podczas debugowania.
Klasyczny development aplikacji webowych oparty jest o renderowanie części klienckiej przez serwer, a właściwie jego fragmentów. MVC (lub jego jakaś inkarnacja) w części serwerowej tworzą totalnie nieczytelny i niespójny generator klienta, z którym obcuje użytkownik i zespół załamanych developerów. Zarządzanie klienckimi assetami przez serwer (taki jak Django ), mimo dobrej implementacji, też nie należy do najprzyjemniejszych. Łatwo o chaos, szczególnie gdy czas developmentu jest krytyczny. Niech serwer robi to, do czego służy najlepiej - niech świadczy usługi za pomocą ustalonego interfejsu. REST , czy też HTTP +JSON , to droga która powinna być standardem.
Elasticsearch na dobrej drodze
Wersja 6
Wersja 6.0 ElasticSearch jest dla mnie szczególna - twórcy wprowadzają zmiany ułatwiające zarządzanie, ale też rezygnują z dawnych błędów, które krytykowałem na łamach tego bloga.
Każdemu polecam migrację do wersji 6.x. Służę pomocą w migracji z wersji 2.x oraz 5.x.
Aktualizacje ElasticSearch - jak wykonać?
Nie można zaprzeczyć, że ElasticSearch jest rozwijany dynamicznie. Tak szybki rozwój produktu nie zawsze jest oczekiwany, bo albo wdrożenie zostaje (z przyczyn obiektywnych) oparte o zamrożoną (i nie wspieraną) wersję, albo konieczne staje się przeprowadzanie migracji do nowszych wersji. Takie operacje trzeba zaplanować, zabudżetować, a na dodatek nie obejdzie się bez downtime i sukcesem jest, gdy przerwa techniczna jest relatywnie krótka.
ElasticSearch nie taki elastyczny
Oryginalny tekst datowany jest na 4.11.2015, a uzupełniony w lipcu 2016
ElasticSearch jest takim samym systemem wyszukiwania, jak każdy inny powstały w przeciągu ostatnich kilkudziesięciu lat. Indeks ma sztywną strukturę i nic tego nie zmieni. Jedyna różnica polega na tym, że tenże indeks jest modyfikowany w locie / w tle, co niesie za sobą sporo, czasem przykrych konsekwencji, choć na początku może wydawać się to świetnym pomysłem.
Nie-typy, czyli “mappingi”
ElasticSearch posiada tzw. “mappingi” . Niektórzy mogą uważać, że są to typy indeksowanych dokumentów. Słowo “typ” z resztą pada w dokumentacji. Ale to nie są typy. Są to elementy grupujące kolumny indeksu w pewne logiczne klasy , które mogą posłużyć jako dodatkowy filtr lub zbiór definicji o analizerach i tokenizerach, oraz mogą mieć znaczenie wydajnościowe (operujemy na jakimś podzbiorze). Można je porównać do widoków znanych z [RDBMS].
Django - migracje bazy, które nie zawsze działają
O kiepskim podejściu do migracji schematów baz danych w Django pisałem już w 2014r. Co jakiś czas jednak temat do mnie wraca, gdyż w niektórych projektach używam (niestety) tego rozwiązania. Powody są różne, a główny to “oszczędność czasu”. No bo trudno zaprzeczyć, że automatyczne wygenerowanie plików z migracjami jest wolniejsze od klepania XML-i Liquibase lub plain SQL , prawda? Sam z tego przecież korzystam…
Jednak bywają takie momenty, gdzie zostaję z tymi migracjami w “czterech literach”, gdzie nawet nie dochodzi ani jeden promyk światła. I taką sytuacją jest m.in. usuwanie atrybutu z modelu, co generuje operację RemoveField.
Prosty automat skonczony w Python
Na GitHub i PyPI wrzuciłem implementację prostego automatu skończonego https://github.com/marcinn/dsm
Instalacja
pip install dsm
Przykład 1: Stany zamówienia w sklepie
Załóżmy, że mamy do oprogramowania automat stanów zamówienia w sklepie:
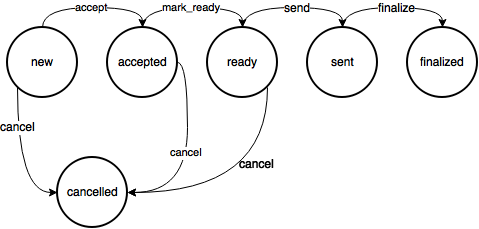
Deklaracja
Wystarczy zdefiniować przejścia za pomocą listy krotek ([stan], [wartość], [nowy stan]), aby automat spełniał swoją rolę.
Deklaracja automatu z przykładu wygląda następująco:
import dsm
class OrderFSM(dsm.StateMachine):
class Meta:
transitions = (
('new', 'accept', 'accepted'),
('new', 'cancel', 'cancelled'),
('accepted', 'mark_ready', 'ready'),
('accepted', 'cancel', 'cancelled'),
('ready', 'send', 'sent'),
('ready', 'cancel', 'cancelled'),
('sent', 'finalize', 'finalized'),
)
initial = 'new'
Symulacja
Kod symulacji:
fsm = OrderFSM()
print 'State: `%s`, trying to accept' % fsm.state
fsm.process('accept')
print 'State: `%s`' % fsm.state
print "Can I send order now? - %s." % ('Yes' if fsm.can('send') else 'No')
print 'Marking as ready.'
fsm.process('mark_ready')
print "Can I send order now? - %s." % ('Yes' if fsm.can('send') else 'No')
fsm.process('send')
print "Order is %s" % fsm.state
print "Trying to cancel order..."
fsm.process('cancel')
Wynik:
RESTful JavaScript client w kwadrans
Próbowałem restful.js, próbowałem jQuery REST client, aż ostatecznie dałem sobie spokój. Dla mnie były jakieś trudne/ciężkie w użyciu. A czym powinien być REST client? Cienkim wrapperem na dowolnego klienta HTTP, który gada z dowolnym url-em.
Na własne potrzeby założyłem, że:
- interfejs ma być banalnie prosty w użyciu
- wystarczy obsługa tylko content type application/json
- ma być obsługa nagłówków, także defaultowych (żeby się nie powtarzać)
- dozwolona jest zależność od jQuery (można się tego względnie łatwo wyzbyć)
Powstał prototyp: