Na GitHub i PyPi wrzuciłem implementację prostego automatu skończonego https://github.com/marcinn/dsm
Instalacja
pip install dsm
Przykład 1: Stany zamówienia w sklepie
Załóżmy, że mamy do oprogramowania automat stanów zamówienia w sklepie:
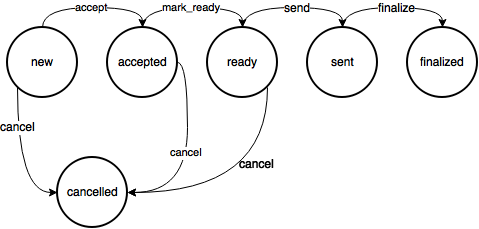
Deklaracja
Wystarczy zdefiniować przejścia za pomocą listy krotek ([stan], [wartość], [nowy stan]), aby automat spełniał swoją rolę.
Deklaracja automatu z przykładu wygląda następująco:
import dsm
class OrderFSM(dsm.StateMachine):
class Meta:
transitions = (
('new', 'accept', 'accepted'),
('new', 'cancel', 'cancelled'),
('accepted', 'mark_ready', 'ready'),
('accepted', 'cancel', 'cancelled'),
('ready', 'send', 'sent'),
('ready', 'cancel', 'cancelled'),
('sent', 'finalize', 'finalized'),
)
initial = 'new'
Symulacja
Kod symulacji:
fsm = OrderFSM()
print 'State: `%s`, trying to accept' % fsm.state
fsm.process('accept')
print 'State: `%s`' % fsm.state
print "Can I send order now? - %s." % ('Yes' if fsm.can('send') else 'No')
print 'Marking as ready.'
fsm.process('mark_ready')
print "Can I send order now? - %s." % ('Yes' if fsm.can('send') else 'No')
fsm.process('send')
print "Order is %s" % fsm.state
print "Trying to cancel order..."
fsm.process('cancel')
Wynik:
State: `new`, trying to accept
State: `accepted`
Can I send order now? - No.
Marking as ready.
Can I send order now? - Yes.
Order is sent
Trying to cancel order...
Traceback (most recent call last):
File "bin/python", line 78, in <module>
exec(compile(__file__f.read(), __file__, "exec"))
File "dsmtest.py", line 39, in <module>
fsm.process('cancel')
File "/home/marcin/src/projekty/archikat/eggs/dsm-0.2-py2.7.egg/dsm.py", line 97, in process
new_state = self._transitions.execute(value, self.state)
File "/home/marcin/src/projekty/archikat/eggs/dsm-0.2-py2.7.egg/dsm.py", line 46, in execute
raise UnknownTransition('Can not find transition for `%s` in state `%s`' % (value, current_state))
dsm.UnknownTransition: Can not find transition for `cancel` in state `sent`
Użycie z Django
Moduł nie ma żadnych zależności od Django, ale można go łatwo zintegrować z modelem. Na przykład tak:
class Order(models.Model):
status = models.CharField(max_length=32)
def change_status(self, operation):
# process() zwraca nowy stan
# nowa instancja OrderFSM() zapewnia prawidłowy stan początkowy
self.status = OrderFSM(initial=self.status).process(operation)
Wywołanie zmiany stanu zamówienia może być następujące:
order = Order.objects.get(pk=666)
try:
order.change_status('send')
except OrderFSM.UnknownTransition:
print "Buuu... :("
Inne zastosowania
W module dsm.py zawarłem przykład automatu sumującego wprowadzane na wejściu cyfry jako przykład użycia w innych celach niż tylko manipulacja stanami jakichś tam dokumentów. DSM emituje zdarzenia i dzięki możliwości rejestrowania callbacków można zbudować coś znacznie ciekawszego.
Przykład 2: Parzysta ilość zer w ciągu
Jako kolejny przykład zaimplementowałem automat sprawdzający, czy liczność zer w ciągu wejściowym jest parzysta, opisany na Wikipedii.
import dsm
class ParityChecker(dsm.StateMachine):
class Meta:
transitions = (
('even', '0', 'odd'),
('even', '1', 'even'),
('odd', '1', 'odd'),
('odd', '0', 'even'),
)
initial = 'even'
pc = ParityChecker()
while True:
pc.reset()
digits = raw_input('Podaj ciag zlozony z zer i jedynek: ')
if not digits:
break
pc.process_many(digits)
print "%sparzysta ilos zer (%s)" % ('Nie' if pc.state=='odd' else '',
digits.count('0'))

